

[ad_1]
Did you know that while the Ahrefs Blog is powered by WordPress, much of the rest of the site is powered by JavaScript like React?
The reality of the current web is that JavaScript is everywhere. Most websites use some kind of JavaScript to add interactivity and improve user experience.
Yet most of the JavaScript used on so many websites won’t impact SEO at all. If you have a normal WordPress install without a lot of customization, then likely none of the issues will apply to you.
Where you will run into issues is when JavaScript is used to build an entire page, add or take away elements, or change what was already on the page. Some sites use it for menus, pulling in products or prices, grabbing content from multiple sources or, in some cases, for everything on the site. If this sounds like your site, keep reading.
We’re seeing entire systems and apps built with JavaScript frameworks and even some traditional CMSes with a JavaScript flair where they’re headless or decoupled. The CMS is used as the backend source of data, but the frontend presentation is handled by JavaScript.
The web has moved from plain HTML – as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
— 308 redirects are better than 301. Change my mind. (@JohnMu) August 8, 2017
I’m not saying that SEOs need to go out and learn how to program JavaScript. I actually don’t recommend it because it’s not likely that you will ever touch the code. What SEOs need to know is how Google handles JavaScript and how to troubleshoot issues.
JavaScript SEO is a part of technical SEO (search engine optimization) that makes JavaScript-heavy websites easy to crawl and index, as well as search-friendly. The goal is to have these websites be found and rank higher in search engines.
JavaScript is not bad for SEO, and it’s not evil. It’s just different from what many SEOs are used to, and there’s a bit of a learning curve.
A lot of the processes are similar to things SEOs are already used to seeing, but there may be slight differences. You’re still going to be looking at mostly HTML code, not actually looking at JavaScript.
All the normal on-page SEO best practices still apply. See our guide on on-page SEO.
You’ll even find familiar plugin-type options to handle a lot of the basic SEO elements, if it’s not already built into the framework you’re using. For JavaScript frameworks, these are called modules, and you’ll find lots of package options to install them.
There are versions for many of the popular frameworks like React, Vue, Angular, and Svelte that you can find by searching for the framework + module name like “React Helmet.” Meta tags, Helmet, and Head are all popular modules with similar functionality and allow for many of the popular tags needed for SEO to be set.
In some ways, JavaScript is better than traditional HTML, such as ease of building and performance. In some ways, JavaScript is worse, such as it can’t be parsed progressively (like HTML and CSS can be), and it can be heavy on page load and performance. Often, you may be trading performance for functionality.
JavaScript isn’t perfect, and it isn’t always the right tool for the job. Developers do overuse it for things where there’s probably a better solution. But sometimes, you have to work with what you are given.
These are many of the common SEO issues you may run into when working with JavaScript sites.
Have unique title tags and meta descriptions
You’re still going to want to have unique title tags and meta descriptions across your pages. Because a lot of the JavaScript frameworks are templatized, you can easily end up in a situation where the same title or meta description is used for all pages or a group of pages.
Check the Duplicates report in Ahrefs’ Site Audit and click into any of the groupings to see more data about the issues we found.
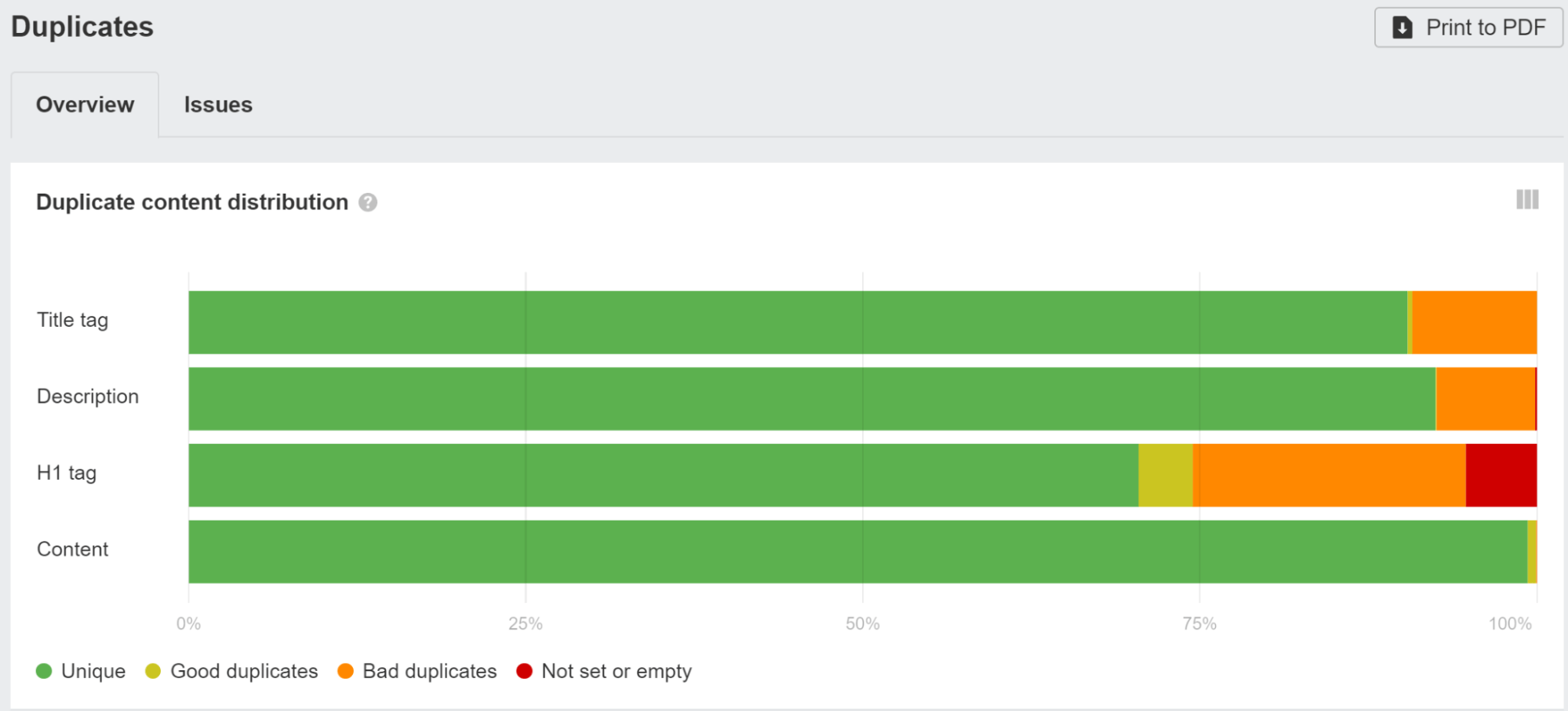
You can use one of the SEO modules like Helmet to set custom tags for each page.
JavaScript can also be used to overwrite default values you may have set. Google will process this and use the overwritten title or description. For users, however, titles can be problematic, as one title may appear in the browser and they’ll notice a flash when it gets overwritten.
If you see the title flashing, you can use Ahrefs’ SEO Toolbar to see both the raw HTML and rendered versions.
Google may not use your titles or meta descriptions anyway. As I mentioned, the titles are worth cleaning up for users. Fixing this for meta descriptions won’t really make a difference, though.
When we studied Google’s rewriting, we found that Google overwrites titles 33.4% of the time and meta descriptions 62.78% of the time. In Site Audit, we’ll even show you which of your title tags Google has changed.
Canonical tag issues
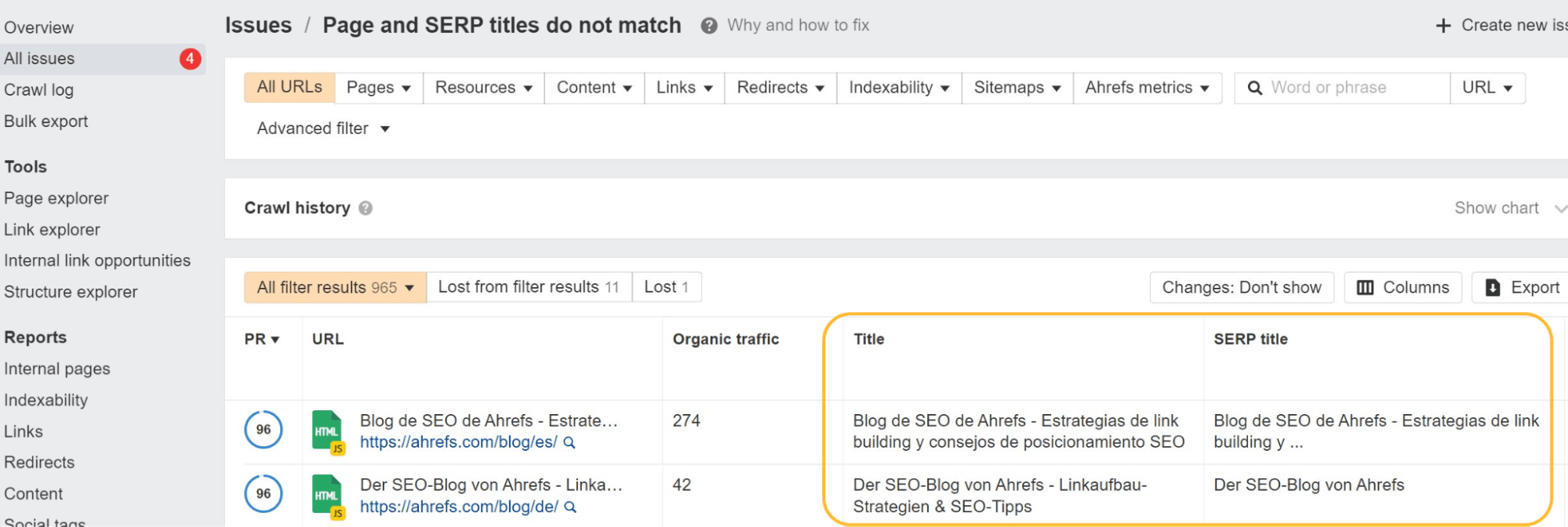
For years, Google said it didn’t respect canonical tags inserted with JavaScript. It finally added an exception to the documentation for cases where there wasn’t already a tag. I caused that change. I ran tests to show this worked when Google was telling everyone it didn’t.
What does the URL Inspection tool say about JavaScript inserted canonicals? Here’s one for https://t.co/rZDpYgwK8r (no canonical in html), which was definitely respected and switched in the SERPs a while back but now even the tools are telling me they see and respect it. @JohnMu pic.twitter.com/vmml2IG7bk
— Patrick Stox (@patrickstox) August 3, 2018
If there was already a canonical tag present and you add another one or overwrite the existing one with JavaScript, then you’re giving them two canonical tags. In this case, Google has to figure out which one to use or ignore the canonical tags in favor of other canonicalization signals.
Standard SEO advice of “every page should have a self-referencing canonical tag” gets many SEOs in trouble. A dev takes that requirement, and they make pages with and without a trailing slash self-canonical.
example.com/page with a canonical of example.com/page and example.com/page/ with a canonical of example.com/page/. Oops, that’s wrong! You probably want to redirect one of those versions to the other.
The same thing can happen with parameterized versions that you may want to combine, but each is self-referencing.
Google uses the most restrictive meta robots tag
With meta robots tags, Google is always going to take the most restrictive option it sees—no matter the location.
If you have an index tag in the raw HTML and noindex tag in the rendered HTML, Google will treat it as noindex. If you have a noindex tag in the raw HTML but you overwrite it with an index tag using JavaScript, it’s still going to treat that page as noindex.
It works the same for nofollow tags. Google is going to take the most restrictive option.
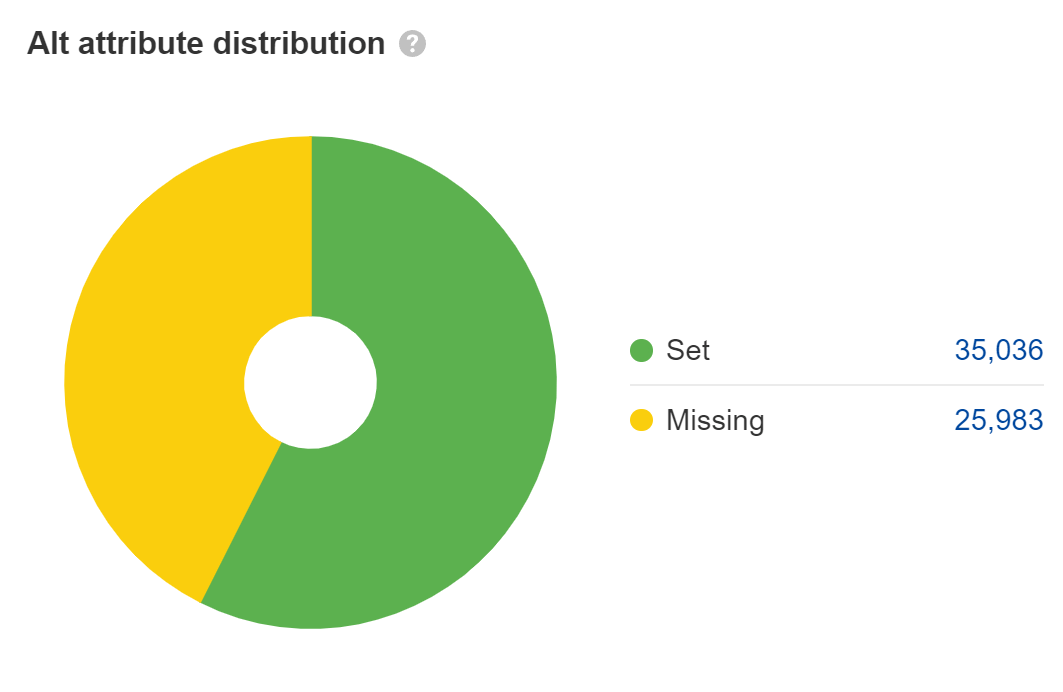
Set alt attributes on images
Missing alt attributes are an accessibility issue, which may turn into a legal issue. Most big companies have been sued for ADA compliance issues on their websites, and some get sued multiple times a year. I’d fix this for the main content images, but not for things like placeholder or decorative images where you can leave the alt attributes blank.
For web search, the text in alt attributes counts as text on the page, but that’s really the only role it plays. Its importance is often overstated for SEO, in my opinion. However, it does help with image search and image rankings.
Lots of JavaScript developers leave alt attributes blank, so double-check that yours are there. Look at the Images report in Site Audit to find these.
Allow crawling of JavaScript files
Don’t block access to resources if they are needed to build part of the page or add to the content. Google needs to access and download resources so that it can render the pages properly. In your robots.txt, the easiest way to allow the needed resources to be crawled is to add:
User-Agent: GooglebotAllow: .jsAllow: .css
Also check the robots.txt files for any subdomains or additional domains you may be making requests from, such as those for your API calls.
If you have blocked resources with robots.txt, you can check if it impacts the page content using the block options in the “Network” tab in Chrome Dev Tools. Select the file and block it, then reload the page to see if any changes were made.
Check if Google sees your content
Many pages with JavaScript functionality may not be showing all of the content to Google by default. If you talk to your developers, they may refer to this as being not Document Object Model (DOM) loaded. This means the content wasn’t loaded by default and might be loaded later with an action like a click.
A quick check you can do is to simply search for a snippet of your content in Google inside quotation marks. Search for “some phrase from your content” and see if the page is returned in the search results. If it is, then your content was likely seen.
Sidenote.
Content that is hidden by default may not be shown within your snippet on the SERPs. It’s especially important to check your mobile version, as this is often stripped down for user experience.
You can also right-click and use the “Inspect” option. Search for the text within the “Elements” tab.
The best check is going to be searching within the content of one of Google’s testing tools like the URL Inspection tool in Google Search Console. I’ll talk more about this later.
I’d definitely check anything behind an accordion or a dropdown. Often, these elements make requests that load content into the page when they are clicked on. Google doesn’t click, so it doesn’t see the content.
If you use the inspect method to search content, make sure to copy the content and then reload the page or open it in an incognito window before searching.
If you’ve clicked the element and the content loaded in when that action was taken, you’ll find the content. You may not see the same result with a fresh load of the page.
Duplicate content issues
With JavaScript, there may be several URLs for the same content, which leads to duplicate content issues. This may be caused by capitalization, trailing slashes, IDs, parameters with IDs, etc. So all of these may exist:
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
If you only want one version indexed, you should set a self-referencing canonical and either canonical tags from other versions that reference the main version or ideally redirect the other versions to the main version.
Check the Duplicates report in Site Audit. We break down which duplicate clusters have canonical tags set and which have issues.
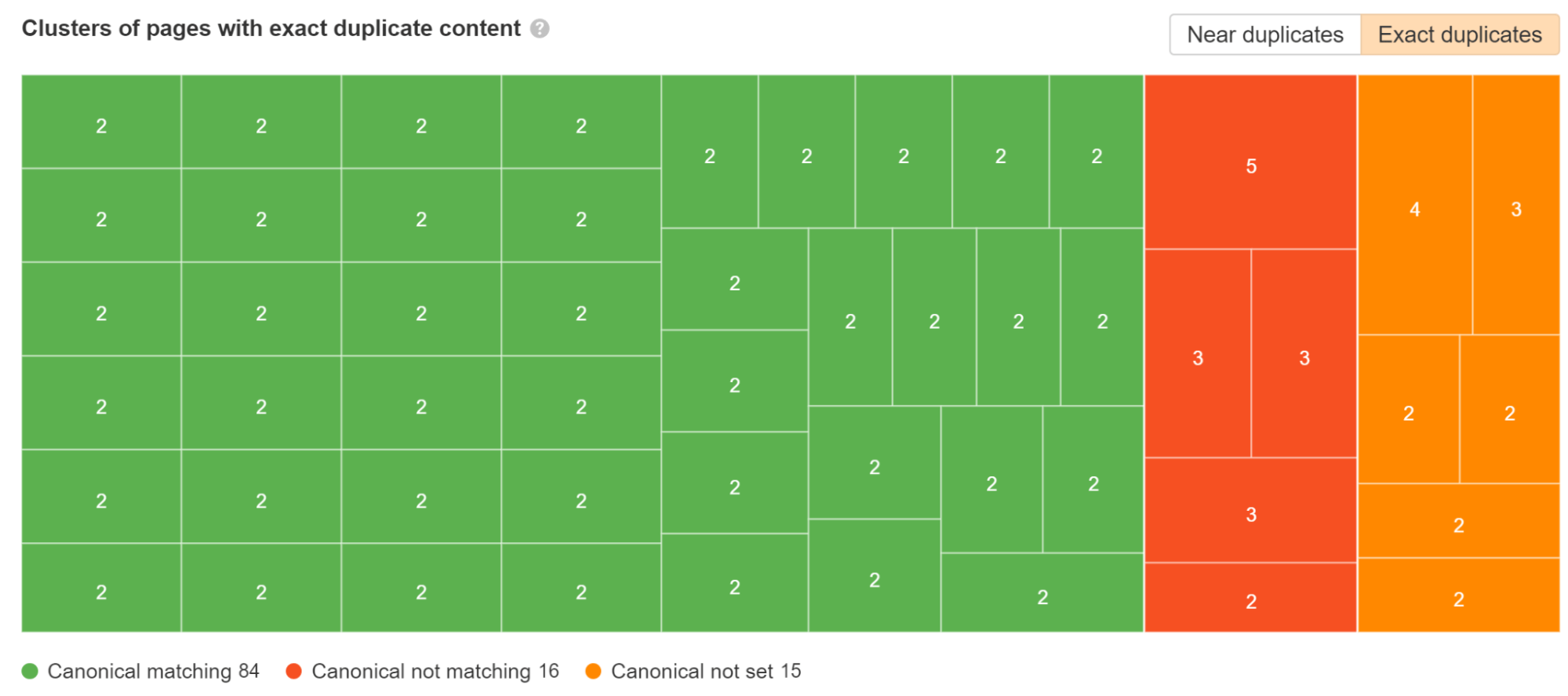
A common issue with JavaScript frameworks is that pages can exist with and without the trailing slash. Ideally, you’d pick the version you prefer and make sure that version has a self-referencing canonical tag and then redirect the other version to your preferred version.
With app shell models, very little content and code may be shown in the initial HTML response. In fact, every page on the site may display the same code, and this code may be the exact same as the code on some other websites.
If you see a lot of URLs with a low word count in Site Audit, it may indicate you have this issue.
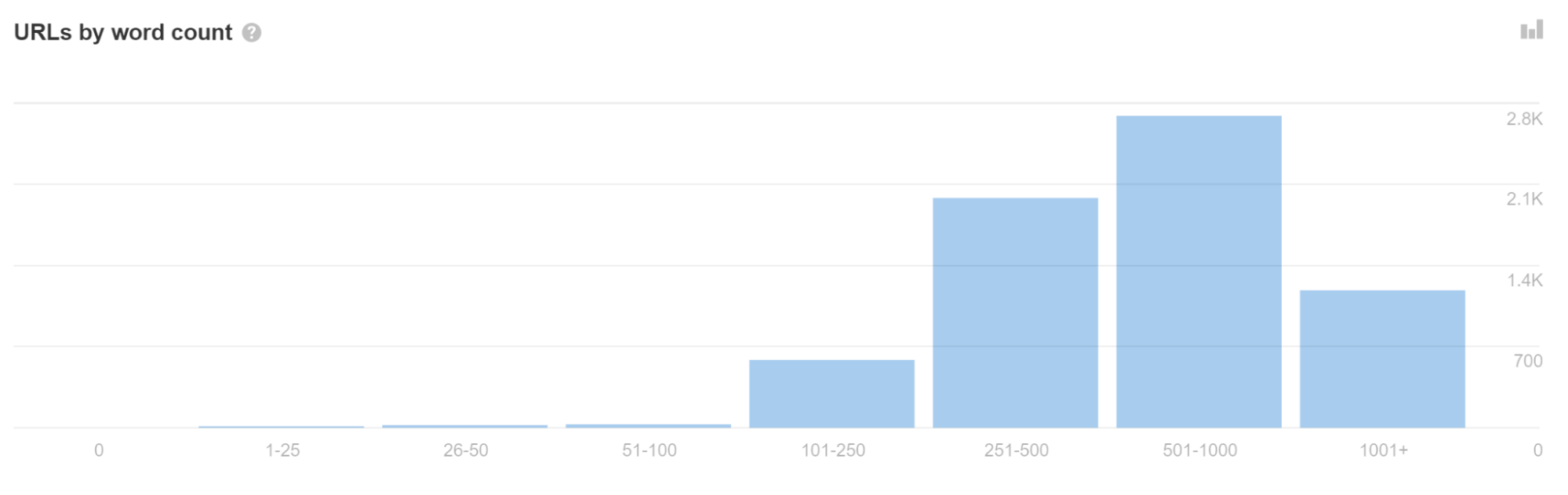
This can sometimes cause pages to be treated as duplicates and not immediately go to rendering. Even worse, the wrong page or even the wrong site may show in search results. This should resolve itself over time but can be problematic, especially with newer websites.
Don’t use fragments (#) in URLs
# already has a defined functionality for browsers. It links to another part of a page when clicked—like our “table of contents” feature on the blog. Servers generally won’t process anything after a #. So for a URL like abc.com/#something, anything after a # is typically ignored.
JavaScript developers have decided they want to use # as the trigger for different purposes, and that causes confusion. The most common ways they’re misused…
[ad_2]
