

[ad_1]
Günlük dosyaları, son beş yılda teknik SEO uzmanlarından artan bir şekilde tanınmaktadır ve bunun iyi bir nedeni vardır.
Arama motorlarının taradığı URL’leri anlamak için en güvenilir bilgi kaynaklarıdır ve teknik SEO ile ilgili sorunları teşhis etmeye yardımcı olacak kritik bilgiler olabilir.
Google, Google Search Console’da yeni özellikler yayınlayarak ve daha önce yalnızca günlükleri analiz ederek kullanılabilecek veri örneklerini görmeyi kolaylaştırarak, bunların öneminin farkındadır.
Ayrıca, Google Arama Avukatı John Mueller, günlük dosyalarının ne kadar iyi bilgi içerdiğini herkese açık bir şekilde belirtti.
@glenngabe Günlük dosyaları çok az, içlerinde çok iyi bilgiler var.
— 🦝 John (kişisel) 🦝 (@JohnMu) 5 Nisan 2016
Günlük dosyalarındaki verilerle ilgili tüm bu yutturmaca ile günlükleri daha iyi anlamak, bunların nasıl analiz edileceğini ve üzerinde çalıştığınız sitelerin bunlardan yararlanıp yararlanamayacağını anlamak isteyebilirsiniz.
Bu makale tüm bunları ve daha fazlasını cevaplayacaktır. İşte tartışacaklarımız:
Sunucu günlük dosyası, gerçekleştirdiği etkinlikleri kaydeden bir sunucu tarafından oluşturulan ve güncellenen bir dosyadır. Popüler bir sunucu günlük dosyası, günlük dosyasına erişimsunucuya yapılan HTTP isteklerinin geçmişini tutan (hem kullanıcılar hem de botlar tarafından).
Geliştirici olmayan biri bir günlük dosyasından bahsettiğinde, genellikle atıfta bulunacakları günlükler erişim günlükleridir.
Ancak geliştiriciler, sunucunun karşılaştığı sorunları bildiren hata günlüklerine bakmak için daha fazla zaman harcarlar.
Yukarıdakiler önemlidir: Bir geliştiriciden günlük talep ederseniz, soracakları ilk şey “Hangileri?” olacaktır.
Öyleyse, günlük dosyası isteklerinde her zaman spesifik olun. Günlüklerin taramayı analiz etmesini istiyorsanız, erişim günlüklerini isteyin.
Erişim günlüğü dosyaları, sunucuya yapılan her istek hakkında aşağıdakiler gibi birçok bilgi içerir:
- IP adresleri
- Kullanıcı aracıları
- URL yolu
- Zaman damgaları (bot/tarayıcı istekte bulunduğunda)
- İstek türü (GET veya POST)
- HTTP durum kodları
Erişim günlüklerine hangi sunucuların dahil olduğu, sunucu türüne ve bazen hangi geliştiricilerin sunucuyu günlük dosyalarında depolamak üzere yapılandırdığına göre değişir. Günlük dosyaları için yaygın biçimler şunları içerir:
- Apache formatı – Bu, Nginx ve Apache sunucuları tarafından kullanılır.
- W3C formatı – Bu, Microsoft IIS sunucuları tarafından kullanılır.
- ELB formatı – Bu, Amazon Elastic Load Balancing tarafından kullanılır.
- Özel biçimler – Birçok sunucu, özel bir günlük biçiminin çıktısını almayı destekler.
Başka formlar da var, ancak karşılaşacağınız ana formlar bunlar.
Artık günlük dosyaları hakkında temel bir anlayışa sahip olduğumuza göre, SEO’dan nasıl yararlandıklarını görelim.
İşte bazı önemli yollar:
- tarama izleme – Arama motorlarının taradığı URL’leri görebilir ve bunu tarayıcı tuzaklarını tespit etmek, tarama bütçesi israfına dikkat etmek veya içerik değişikliklerinin ne kadar hızlı alındığını daha iyi anlamak için kullanabilirsiniz.
- Durum kodu raporlaması – Bu, özellikle düzeltme hatalarına öncelik vermek için kullanışlıdır. Bir 404’ünüz olduğunu bilmek yerine, bir kullanıcının/arama motorunun 404 URL’sini tam olarak kaç kez ziyaret ettiğini görebilirsiniz.
- Trend analizi – Zaman içinde bir URL’ye, sayfa türüne/site bölümüne veya sitenizin tamamına yapılan taramayı izleyerek, değişiklikleri tespit edebilir ve olası nedenleri araştırabilirsiniz.
- Yetim sayfa keşfi – Yetim sayfaları keşfetmek için günlük dosyalarından ve kendiniz çalıştırdığınız bir site taramasından gelen verileri çapraz analiz edebilirsiniz.
Tüm siteler, günlük dosyası analizinden bir dereceye kadar yararlanacaktır, ancak fayda miktarı büyük ölçüde değişir site boyutuna bağlı olarak.
Bu, günlük dosyaları size yardımcı olarak öncelikle sitelere fayda sağladığındandır. daha iyi üstesinden gelmek emekleme. Google kendisi devletler tarama bütçesini yönetmek, daha büyük ölçekli veya sık sık değişen sitelerin fayda sağlayacağı bir şeydir.
Aynısı günlük dosyası analizi için de geçerlidir.
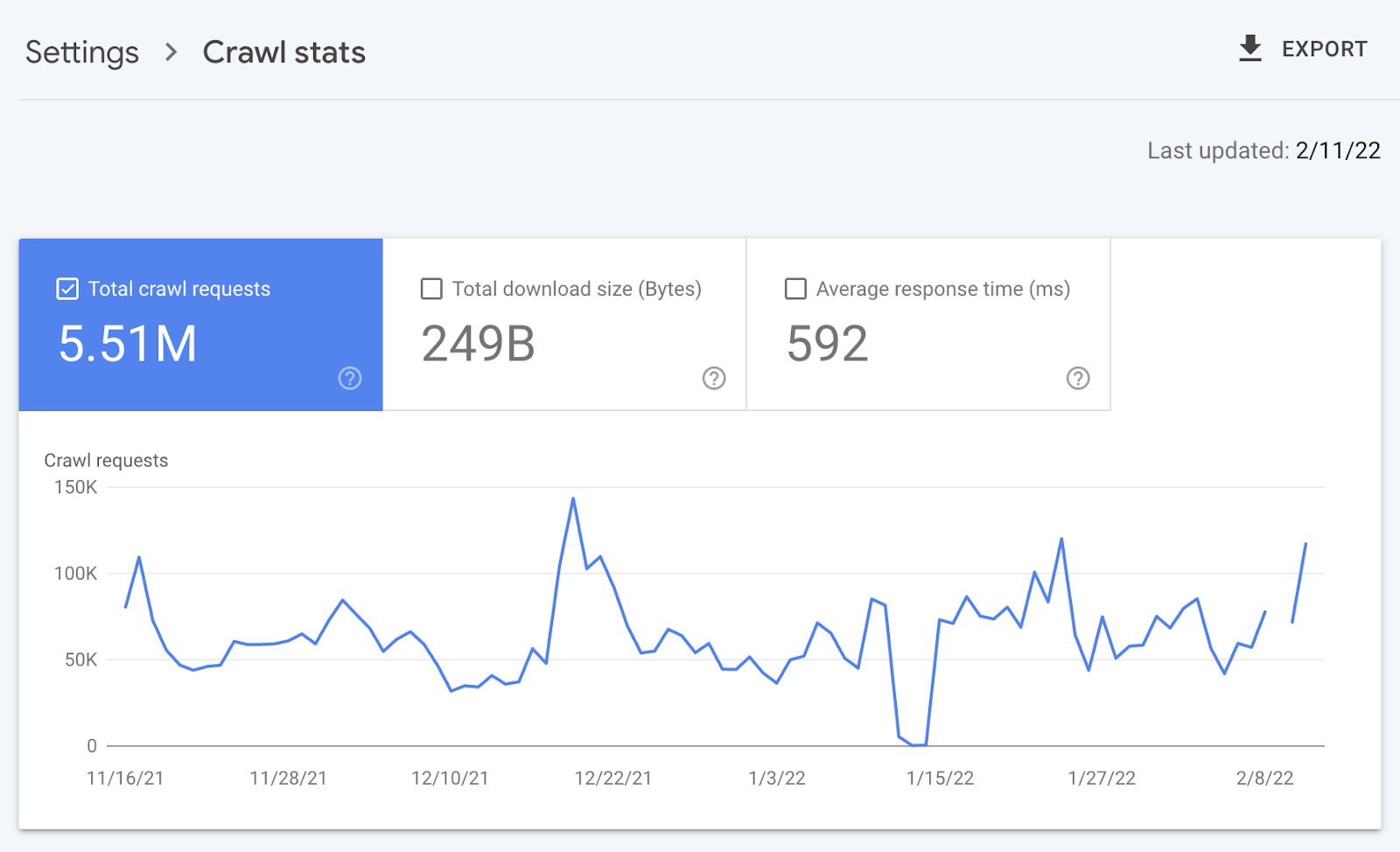
Örneğin, daha küçük siteler büyük olasılıkla Google Arama Konsolunda sağlanan “Tarama istatistikleri” verilerini kullanabilir ve bir günlük dosyasına dokunmaya gerek kalmadan yukarıda belirtilen tüm avantajlardan yararlanabilir.
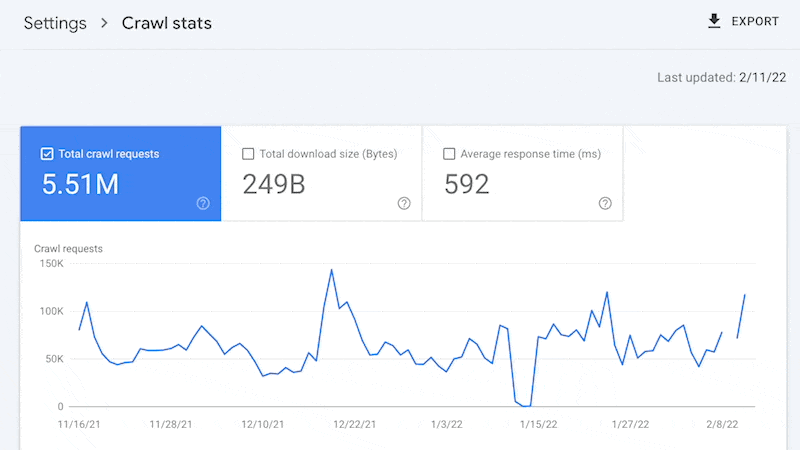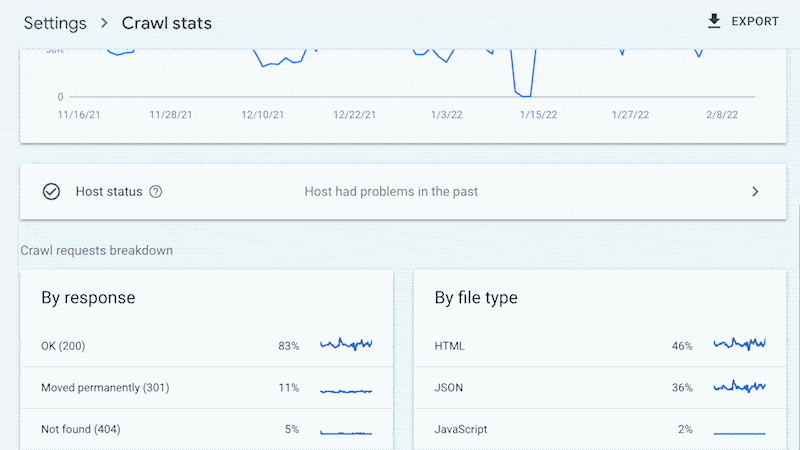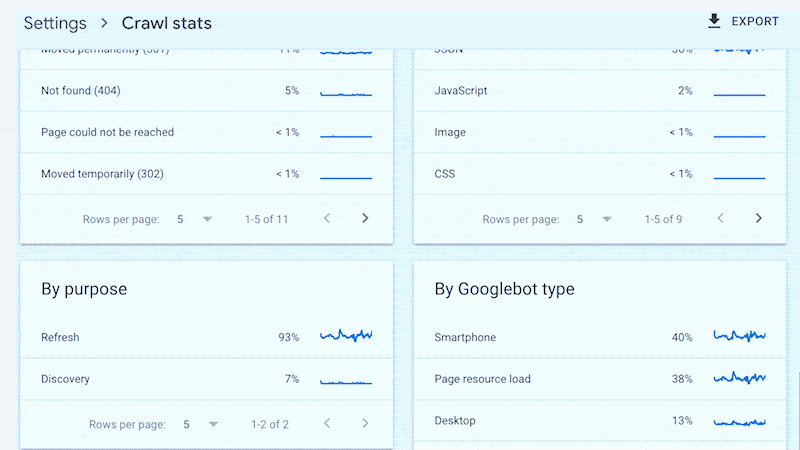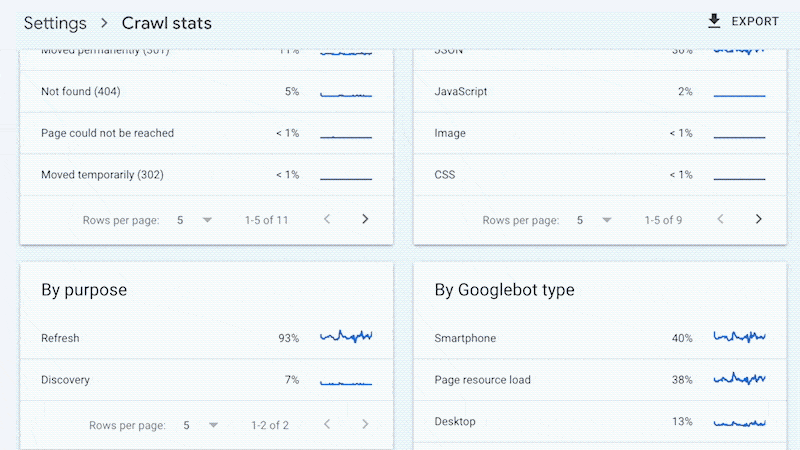
Evet, Google size şunları sağlamaz: tüm URL’ler taranır (günlük dosyalarında olduğu gibi) ve trend analizi üç aylık verilerle sınırlıdır.
Ancak, nadiren değişen daha küçük siteler de daha az süregelen teknik SEO’ya ihtiyaç duyar. Bir site denetçisinin sorunları keşfetmesi ve teşhis etmesi muhtemelen yeterli olacaktır.
Örneğin, bir site tarayıcısından, XML site haritalarından, Google Analytics’ten ve Google Arama Konsolundan yapılan çapraz analiz, büyük olasılıkla tüm yetim sayfaları keşfedecektir.
Dahili bağlantılardan hata durum kodlarını keşfetmek için bir site denetçisi de kullanabilirsiniz.
Bunu belirtmemin birkaç temel nedeni var:
- Günlük dosyalarına erişim ele geçirmek kolay değil (bundan sonra daha fazlası).
- Nadiren değişen küçük siteler için, günlük dosyalarının faydası o kadar fazla değildir, yani SEO odaklarının büyük olasılıkla başka yerlere gideceği anlamına gelir.
Çoğu durumda, günlük dosyalarını analiz etmek için önce Giriş bir geliştiriciden dosyaları günlüğe kaydetmek için.
Geliştiricinin, muhtemelen dikkatinize sunacakları birkaç sorunu olacaktır. Bunlar şunları içerir:
- Kısmi veri – Günlük dosyaları, birden çok sunucuya dağılmış kısmi verileri içerebilir. Bu genellikle geliştiriciler bir kaynak sunucu, yük dengeleyiciler ve bir CDN gibi çeşitli sunucular kullandığında olur. Tüm günlüklerin doğru bir resmini elde etmek, muhtemelen tüm sunuculardan erişim günlüklerini derlemek anlamına gelecektir.
- Dosya boyutu – Yüksek trafiğe sahip siteler için erişim günlüğü dosyaları, petabayt olmasa da terabayt cinsinden sonuçlanabilir ve bu da onları aktarmayı zorlaştırır.
- Gizlilik/uyum – Günlük dosyaları, kişisel olarak tanımlanabilir bilgiler (PII) olan kullanıcı IP adreslerini içerir. Kullanıcı bilgilerinin sizinle paylaşılabilmesi için kaldırılması gerekebilir.
- Depolama geçmişi – Dosya boyutu nedeniyle, geliştiriciler erişim günlüklerini yalnızca birkaç gün saklanacak şekilde yapılandırmış olabilir, bu da onları eğilimleri ve sorunları saptamak için kullanışlı hale getirmez.
Bu sorunlar, özellikle geliştiricilerin zaten uzun bir öncelik listesi varsa (genellikle böyledir), günlük dosyalarını depolamanın, birleştirmenin, filtrelemenin ve aktarmanın geliştirme çabasına değip değmediğini sorgulayacaktır.
Geliştiriciler, diğer SEO odakları arasında öncelik vermeniz gerekecek olan, geliştiricilerin buna neden zaman ayırması gerektiğine dair bir vaka açıklamak/oluşturmak için büyük olasılıkla SEO’ya yüklenecektir.
Bu sorunlar tam olarak neden günlük dosyası analizi sık yapılmaz.
Geliştiricilerden aldığınız günlük dosyaları da genellikle popüler günlük dosyası analiz araçları tarafından desteklenmeyen şekillerde biçimlendirilir ve bu da analizi daha zor hale getirir.
Neyse ki, bu süreci basitleştiren yazılım çözümleri var. Benim favorim, günlük dosyalarını bir yerde depolayabilen bir Cloudflare uygulaması olan Logflare. BigQuery veritabanı sahip olduğun.
Şimdi günlüklerinizi analiz etmeye başlama zamanı.
Bunu özellikle Logflare bağlamında nasıl yapacağınızı size göstereceğim; ancak günlük verilerinin nasıl kullanılacağına ilişkin ipuçları tüm günlüklerle çalışır.
Birazdan paylaşacağım şablon da herhangi bir günlükle çalışıyor. Veri sayfalarındaki sütunların eşleştiğinden emin olmanız yeterlidir.
1. Logflare’ı ayarlayarak başlayın (isteğe bağlı)
Logflare’ın kurulumu basittir. Ve BigQuery entegrasyonu ile verileri uzun süreli depolar. Verilerin sahibi siz olacaksınız ve bu verileri herkes için kolayca erişilebilir hale getireceksiniz.
Bir zorluk var. Cloudflare sunucularını kullanmak ve DNS’inizi orada yönetmek için alan adı sunucularınızı değiştirmeniz gerekir.
Çoğu için bu iyi. Ancak, daha kurumsal düzeyde bir siteyle çalışıyorsanız, sunucu altyapı ekibini, günlük analizini basitleştirmek için ad sunucularını değiştirmeye ikna etmeniz pek olası değildir.
Logflare’in nasıl çalıştırılacağına dair her adımı atmayacağım. Ancak başlamak için tek yapmanız gereken kontrol panelinizin Cloudflare Apps bölümüne gitmek.
Ve sonra Logflare’ı arayın.
Bu noktadan sonraki kurulum kendiliğinden açıklayıcıdır (bir hesap oluşturun, projenize bir ad verin, gönderilecek verileri seçin, vb.). İzlemenizi önerdiğim tek ekstra kısım, Logflare’nin BigQuery’yi kurma kılavuzu.
Ancak unutmayın ki, BigQuery’nin bir maliyeti var bu, yaptığınız sorgulara ve sakladığınız veri miktarına dayanır.
Kenar notu.
BigQuery arka ucunun önemli bir avantajının, verilere sahip olmak. Bu, Logflare’i PII benzeri IP adresleri göndermeyecek ve bir SQL sorgusu kullanarak BigQuery’den PII’yi silecek şekilde yapılandırarak PII sorunlarını aşabileceğiniz anlamına gelir.
2. Googlebot’u doğrulayın
Artık günlük dosyalarını depoladık (Logflare veya alternatif bir yöntemle). Ardından, analiz etmek istediğimiz kullanıcı aracılarından günlükleri tam olarak çıkarmamız gerekiyor. Çoğu için bu, Googlebot olacaktır.
Bunu yapmadan önce, atlamamız gereken bir engel daha var.
Birçok bot, güvenlik duvarlarını (eğer varsa) geçmek için Googlebot gibi davranır. Ek olarak, bazı denetleme araçları, sitenizin kullanıcı aracısı için döndürdüğü içeriğin doğru bir yansımasını elde etmek için aynı şeyi yapar; bu, sunucunuz Googlebot için farklı HTML döndürüyorsa, ör. dinamik oluşturma.
Logflare kullanmıyorum
Logflare kullanmıyorsanız, Googlebot’u tanımlamak, isteğin Google’dan geldiğini doğrulamak için ters DNS araması gerektirecektir.
Google’ın kullanışlı bir kılavuzu var Googlebot’u burada manuel olarak doğrulama hakkında.
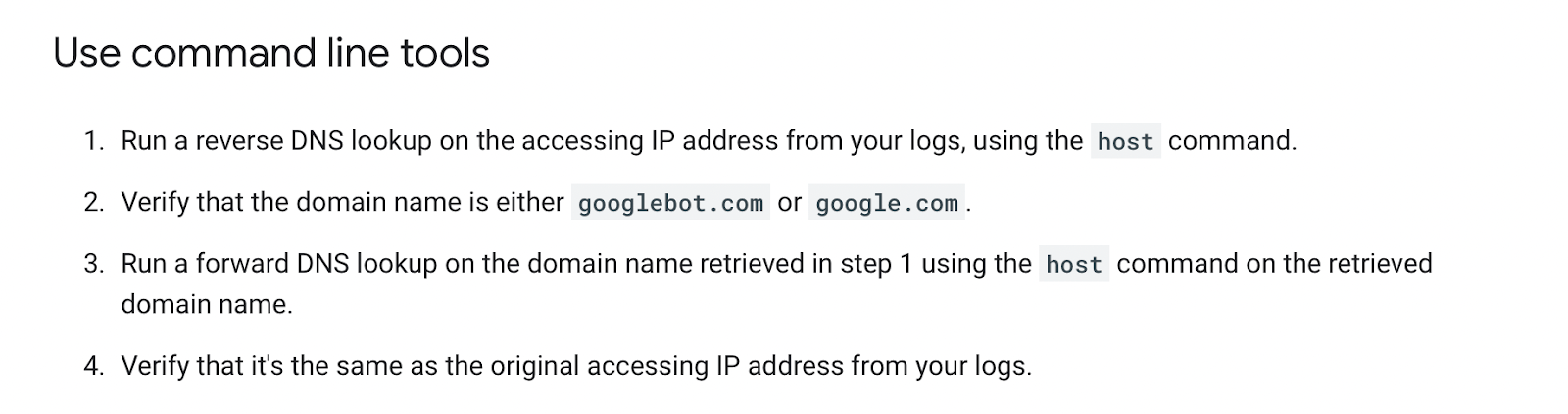
Bunu, bir ters IP arama aracı kullanarak ve döndürülen alan adını kontrol ederek bir kereye mahsus olarak yapabilirsiniz.
Ancak bunu log dosyalarımızdaki tüm satırlar için toplu olarak yapmamız gerekiyor. Bu da gerektirir bir listeden IP adreslerini eşleştirmeniz Google tarafından sağlanmaktadır.
Bunu yapmanın en kolay yolu, sahte botları engelleyen (günlük dosyalarınızda daha az sayıda/hiç sahte Googlebot olmamasıyla sonuçlanır) üçüncü taraflarca sağlanan sunucu güvenlik duvarı kural kümelerini kullanmaktır. Nginx için popüler olanlardan biri “Nginx Ultimate Bad Bot Blocker”dır.
Alternatif olarak, not edeceğiniz bir şey Googlebot IP’leri listesinde IPV4 adreslerinin tümü “66” ile başlar.
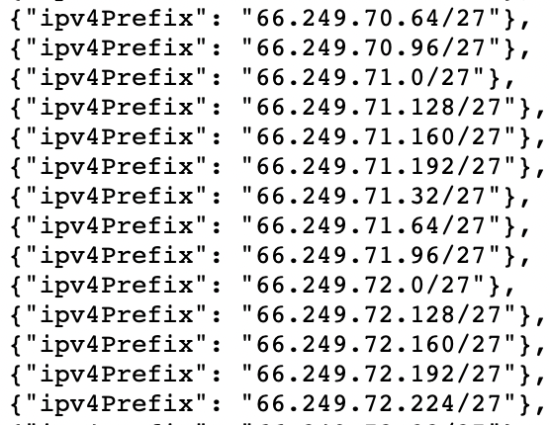
%100 doğru olmasa da, günlüklerinizdeki verileri analiz ederken “6” ile başlayan IP adreslerini filtreleyerek Googlebot’u kontrol edebilirsiniz.
Cloudflare/Logflare kullanıyorum
Cloudflare’nin profesyonel planı (şu anda ayda 20 ABD doları), sahte Googlebot isteklerinin sitenize erişmesini engelleyebilecek yerleşik güvenlik duvarı özelliklerine sahiptir.
Cloudflare varsayılan olarak bu özellikleri devre dışı bırakır, ancak şuraya giderek bunları bulabilirsiniz: Güvenlik Duvarı > Yönetilen Kurallar > etkinleştirme “Cloudflare Özel Ürünleri” > seçme “ileri”:

Ardından, arama türünü “Açıklama”dan “Kimlik”e değiştirin ve “100035”i arayın.
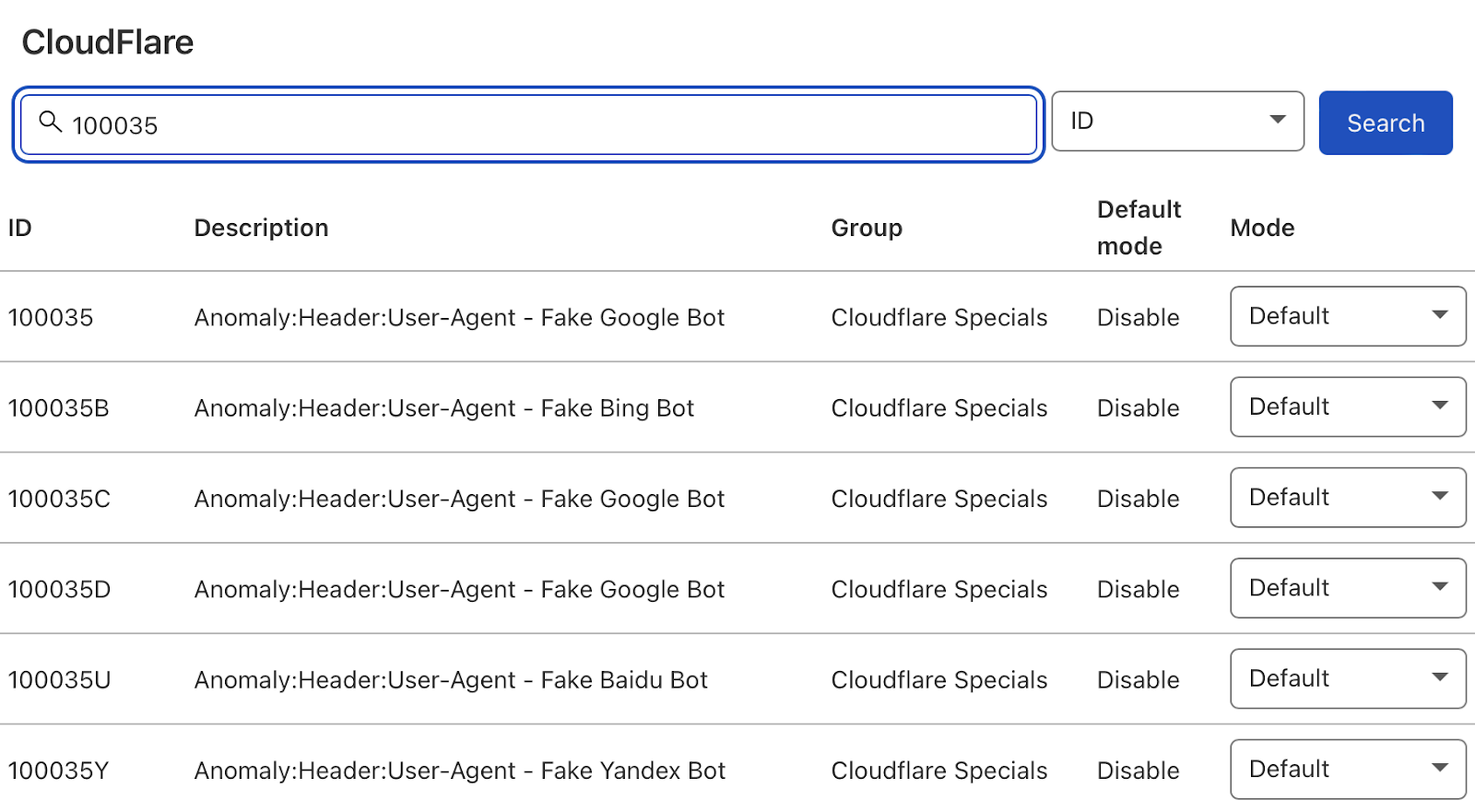
Cloudflare şimdi size sahte arama botlarını engelleme seçeneklerinin bir listesini sunacak. İlgilileri “Engelle” olarak ayarlayın ve Cloudflare, arama botu kullanıcı aracılarından gelen tüm isteklerin meşru olup olmadığını kontrol ederek günlük dosyalarınızı temiz tutar.
3. Günlük dosyalarından veri ayıklayın
Son olarak, artık günlük dosyalarına erişimimiz var ve günlük dosyalarının gerçek Googlebot isteklerini doğru bir şekilde yansıttığını biliyoruz.
Büyük olasılıkla e-tablolara alışacağınız için günlük dosyalarınızı Google E-Tablolar/Excel’de analiz etmenizi öneririm ve günlük dosyalarını site taraması gibi diğer kaynaklarla çapraz analiz etmek kolaydır.
Bunu yapmanın tek bir doğru yolu yoktur. Aşağıdakileri kullanabilirsiniz:
Bunu bir Data Studio raporu içinde de yapabilirsiniz. Data Studio’yu zaman içindeki verileri izlemek için yararlı buluyorum ve teknik denetim sırasında Google Sheets/Excel tek seferlik bir analiz için daha iyi.
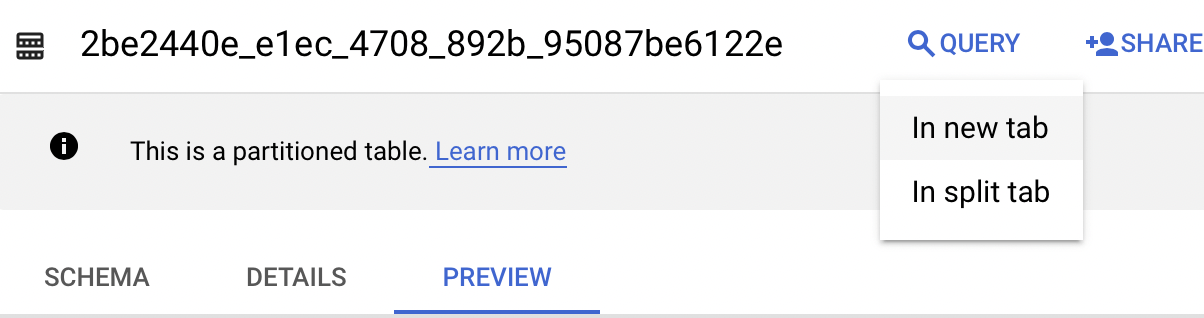
BigQuery’yi açın ve projenize/veri kümenize gidin.
“Sorgu” açılır menüsünü seçin ve yeni bir sekmede açın.
Ardından, analiz edeceğiniz verileri çıkarmak için biraz SQL yazmanız gerekecek. Bunu kolaylaştırmak için önce sorgunun FROM bölümünün içeriğini kopyalayın.

Daha sonra aşağıda sizin için yazdığım sorgunun içine bunu ekleyebilirsiniz:
SELECT DATE(timestamp) AS Date, req.url AS URL, req_headers.cf_connecting_ip AS IP, req_headers.user_agent AS User_Agent, resp.status_code AS Status_Code, resp.origin_time AS Origin_Time, resp_headers.cf_cache_status AS Cache_Status, resp_headers.content_type AS Content_Type
FROM `[Add Your from address here]`,
UNNEST(metadata) m,
UNNEST(m.request) req,
UNNEST(req.headers) req_headers,
UNNEST(m.response) resp,
UNNEST(resp.headers) resp_headers
WHERE DATE(timestamp) >= "2022-01-03" AND (req_headers.user_agent LIKE '%Googlebot%' OR req_headers.user_agent LIKE '%bingbot%')
ORDER BY...
[ad_2]
