

[ad_1]
Quicksand awaits unsuspecting SEOs when they start working on a website with a long history.
These pits of technical site errors, littered by several generations of previous agencies, slow down and hinder SEO efforts and progress.
And when you’re the one tasked to clean it up, finding the quick fixes is your number one task.
So, you may start with a basic site audit and see several orphan pages. You’ve probably heard that orphan pages are bad for a site but do not fully understand what they are and how to fix them.
In this article, you’ll learn:
Orphan pages are pages that search engines may have difficulty discovering because they have no internal links from elsewhere on your website.
These URLs tend to fall through the cracks because search engine crawlers can only discover pages from the sitemap file or external backlinks, and users can only get to the page if they know the URL.
Usually, orphan pages are accidental and occur for various reasons. The most common cause is not having processes for site migrations, navigation changes, site redesigns, out-of-stock products, testing, or dev pages.
Orphan pages may also be intentional, as with promotional and paid advertising landing pages, or any instance where you do not want the page to be part of the user journey.
Search engines have a hard time finding orphan pages because they use links to help discover new content and understand the page’s significance.
Here’s what Google says:
Google searches the web with automated programs called crawlers, looking for pages that are new or updated. […] We find pages by many different methods, but the main method is following links from pages that we already know about.
For example, let’s say you publish a new web page and forget to link to it from elsewhere on your site. If the page isn’t in your sitemap and has no backlinks, Google will not find or index it. That’s because their web crawler doesn’t know that it exists.
Even worse, the page cannot receive PageRank.
If you haven’t heard of the term “PageRank” before, it’s a big deal.
Generally speaking, PageRank is Google’s way of understanding the significance of the page by counting the number of “votes” a page gets. You can read more about how PageRank works and affects SEO here.
To find orphan pages on your site, you need to compare a list of crawlable URLs (what Google can find) with a list of URLs people are hitting on your site.
This may sound quite technical, but don’t be discouraged. We have broken down how to find orphan pages into three easy steps using tools you’re familiar with.
1. Find crawlable URLs
There are a lot of tools you can use to gather a list of all crawlable URLs. We’re going to use Ahrefs’ Site Audit because it’s completely free with an Ahrefs Webmaster Tools account and you have the option to use external backlinks as a source to find even more URLs.
Here’s how to do it:
- Go to Site Audit.
- Click + New Project.
- Follow the prompts until step 3. Click on the URL sources tab and check Backlinks as a URL source in addition to the default settings.
- Click Continue, follow the instructions to complete the setup, then run the crawl.
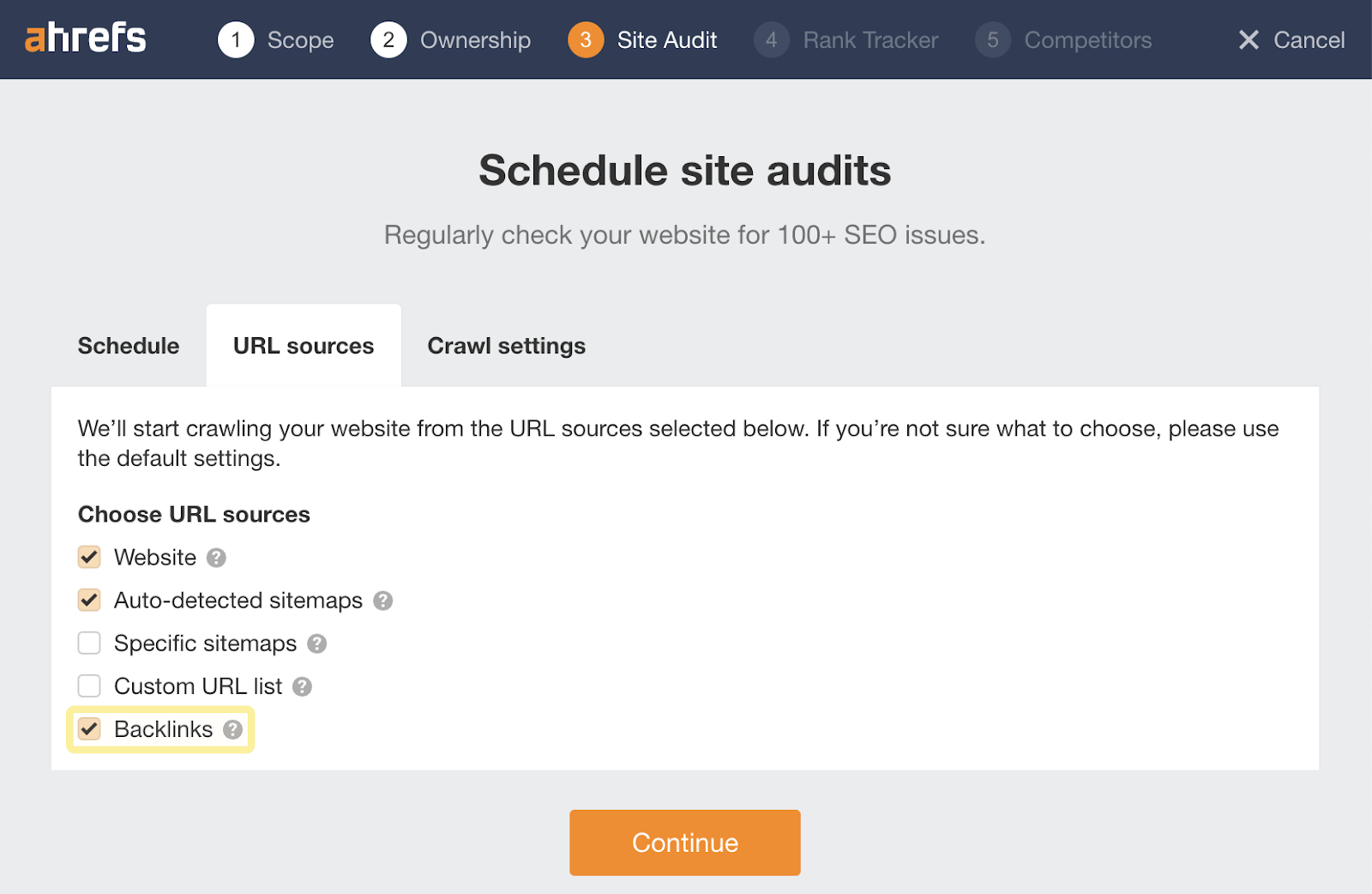
Backlink data is useful for finding orphan pages because it brings URLs from Ahrefs’ link index into the mix.
If a page does not have any internal links, a basic crawler won’t find it.
But, if a page has a backlink, Ahrefs will find the URL on your site and know that the crawl found no internal links, so it must be an orphan page.
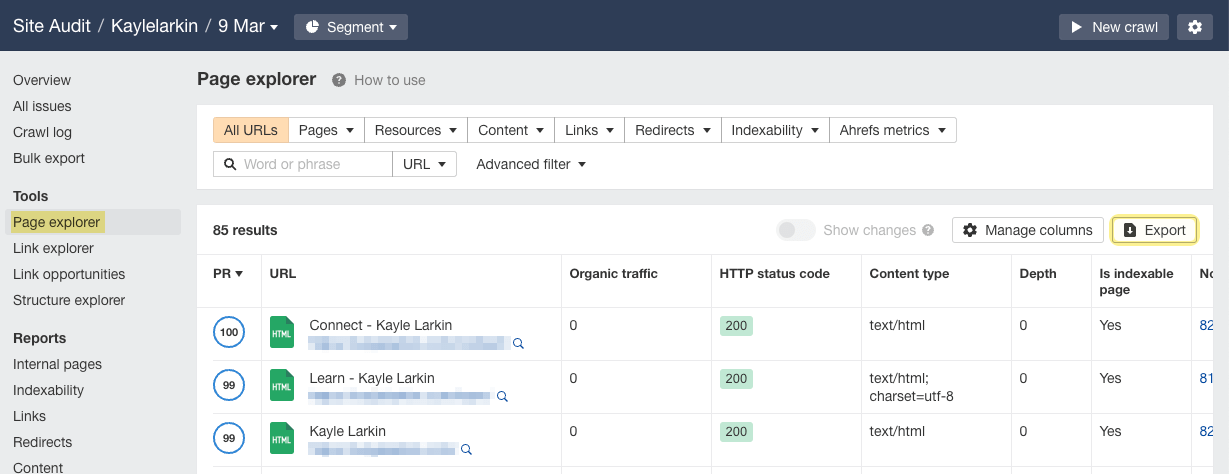
When the site audit is complete, export all internal pages from Page Explorer and save them. You’ll use this in step 3.
Before we continue…
As Site Audit uses both sitemaps and backlinks as URL sources, it does a reasonable job of finding orphan pages for you without any extra work. To see them, go to Page Explorer, click Links, and select Orphan pages:
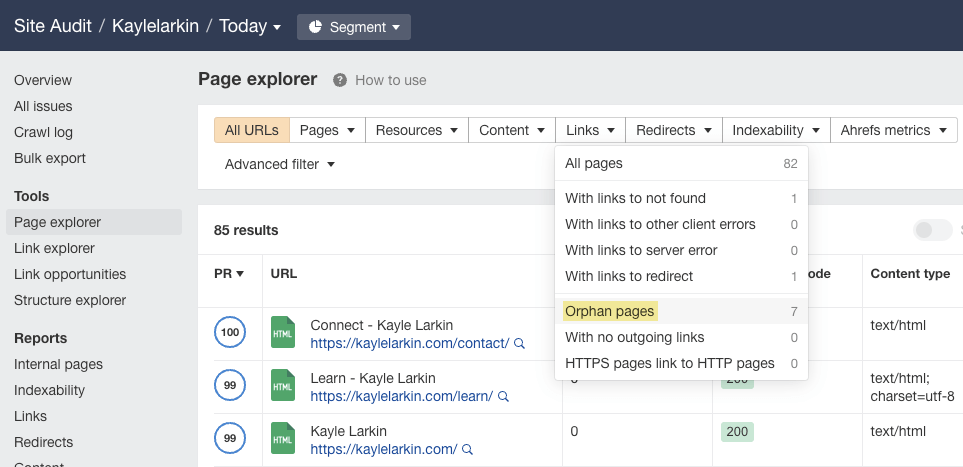
However, you’ll only see orphan pages found via backlinks or sitemaps here. If you have orphan pages not included in sitemaps and without backlinks, Ahrefs won’t be able to find them.
Keep reading if you think this may be the case for you and want to dig a little deeper for orphan pages.
2. Find URLs with hits
The next step is getting a list of all the URLs with hits on our site.
There are quite a few ways to do this, and it’s always best to use as many data sources as you have access to.
If you have access, log files work well because they are server-side data which is more accurate. We won’t be going into the nitty-gritty of accessing these because it depends on how the server is set up.
But if you choose to go this route, here are three official guides for common server types:
In this article, we will use Google Analytics (GA4) and Google Search Console because the process is basically the same for everyone.
Here’s how to find URLs with hits in Google Analytics (GA4):
- Log in to your Data Studio account.
- Start a new blank report.
- Connect Google Analytics as your data source.
- Choose the account you’re analyzing > select GA4 property.
- Add a basic table to your report.
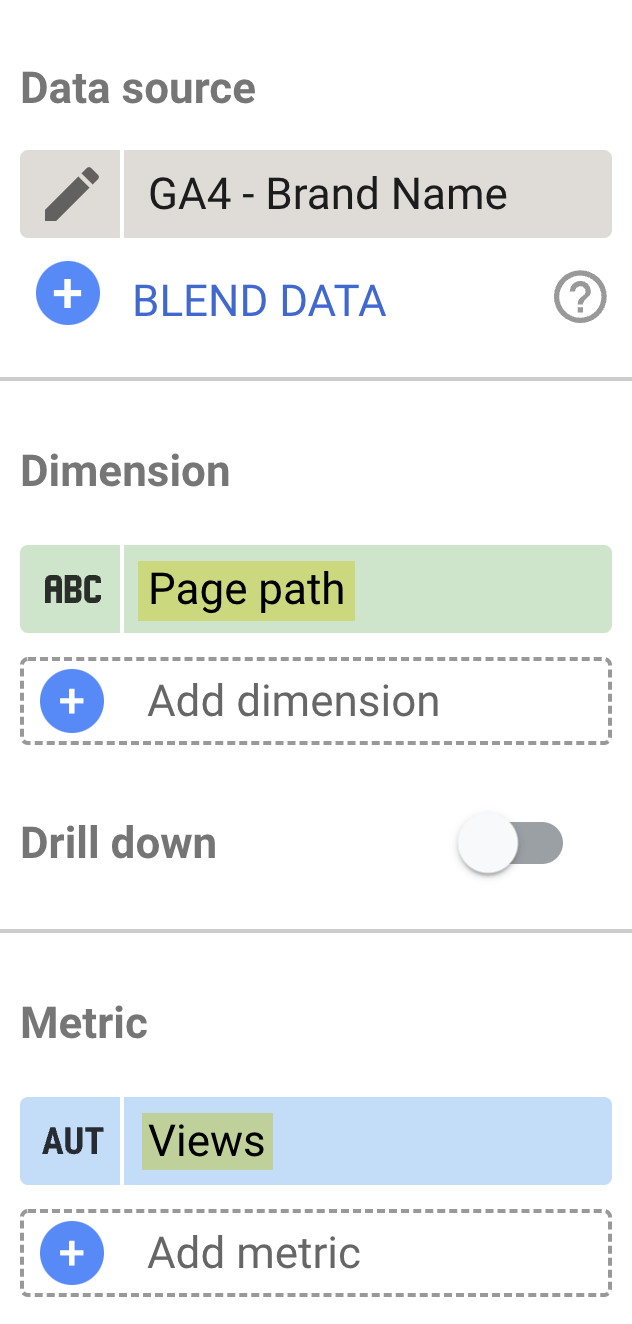
- Set data source to the GA4 property created in step 4.
- Set dimension to Page path.
- Set metric to Views.
- Sort by Views in descending order.
- Set default date range to before GA4 was installed on the site.
To export the results from your table, click the three vertical dots in the top right corner and hit Export. Save with a helpful name like “date_GA_URLs_people_are_hitting_brandname” because you will need it again in just a bit.
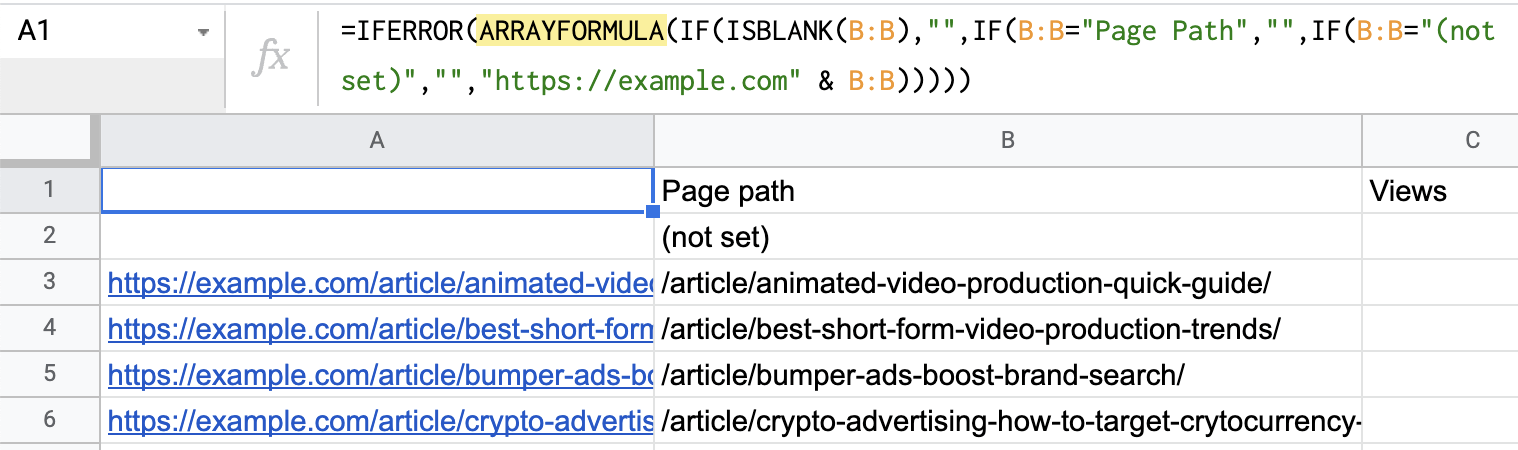
Because we exported the page path and not the full page URL, we need to add the domain to the beginning of all cells in our spreadsheet. This is easy enough in Google sheets. Just import the CSV into a blank sheet, insert a new column to the left, and paste this formula into cell A1 (make sure to replace example.com with your domain):
=IFERROR(ARRAYFORMULA(IF(ISBLANK(B:B),"",IF(B:B="Page Path","",IF(B:B="(not set)","","https://example.com" & B:B)))))
As multiple URL sources are always best, we will also pull data from Google Search Console (GSC).
GSC limits exports to the first 1,000 URLs, but Google Data Studio has a neat little trick that allows you to pull more.
Here’s how to do it:
- Reopen your Data Studio report.
- Start a new page (command + M).
- Open Resource > Manage added data sources.
- Click ADD A DATA SOURCE.
- Select Search Console.
- Choose the site you’re analyzing > URL impression > web.
- Add a basic table to your report.
- Set dimension to Landing page.
- Set metric to Impressions.
- Expand rows per page to 5,000.
- Edit the date range to view at least the past three months.
- Export the results from your table.
Name your sheet something helpful like “date GSC_URLs_people_are_hitting_brandname” because you’ll need it again in a moment.
Now, combine all the URLs people are hitting from your different sources into one spreadsheet and clean up the data by removing duplicates.
3. Cross-reference the two URL sources
You are in the home stretch! The last step is cross-referencing crawlable URLs (from Ahrefs’ Site Audit) and URLs with hits (from GA and GSC). To do this, create a blank Google Sheet and create three tabs. Label them crawl, hits, and cross reference.

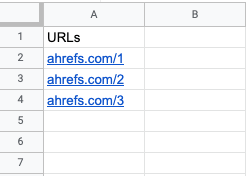
In the first sheet, crawl, copy and paste all of the crawlable URLs from Ahrefs Site Audit.
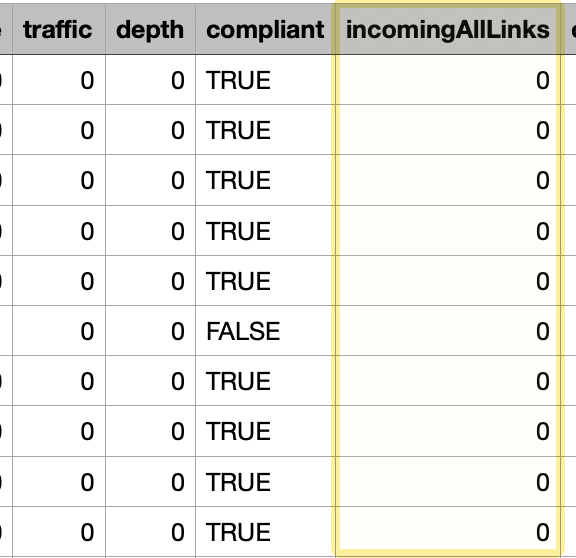
To find these, open the exported CSV from step 1 and filter for results with incomingAllLinks equal to zero. This is super important because these are orphan pages, so including them in the “crawl” tab will lead to inaccurate results when cross-referencing.
Instead, you should copy these URLs and add them to the “hits” tab.
Next, copy and paste the remaining URLs from the Ahrefs export into the crawl tab of your Google Sheet.
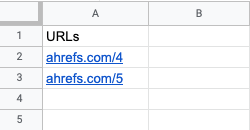
In the second sheet, hits, copy/paste all URLs from step 2. These are the pages you found using Google Analytics, Google Search Console, or your site log files. It includes web pages that users have visited.
In the third sheet, cross reference, enter the following function into the first cell:
=UNIQUE(FILTER(hits!A:A, ISNA(MATCH (hits!A:A, crawl!A:A, 0))))
Hit enter. The function will automatically pull all of your orphan pages for easy analysis.
Marketers often make the mistake of simply adding internal links to all orphan pages across the board.
The main issue with this approach is that just because a quick fix can be applied across all pages does not mean it should be.
Some orphan pages are intentional, like PPC landing pages, while others can just be removed, like test pages.
We don’t want to waste resources fixing something that’s not broken or is unlikely to have a positive impact.
To help solve this problem, use this decision tree:
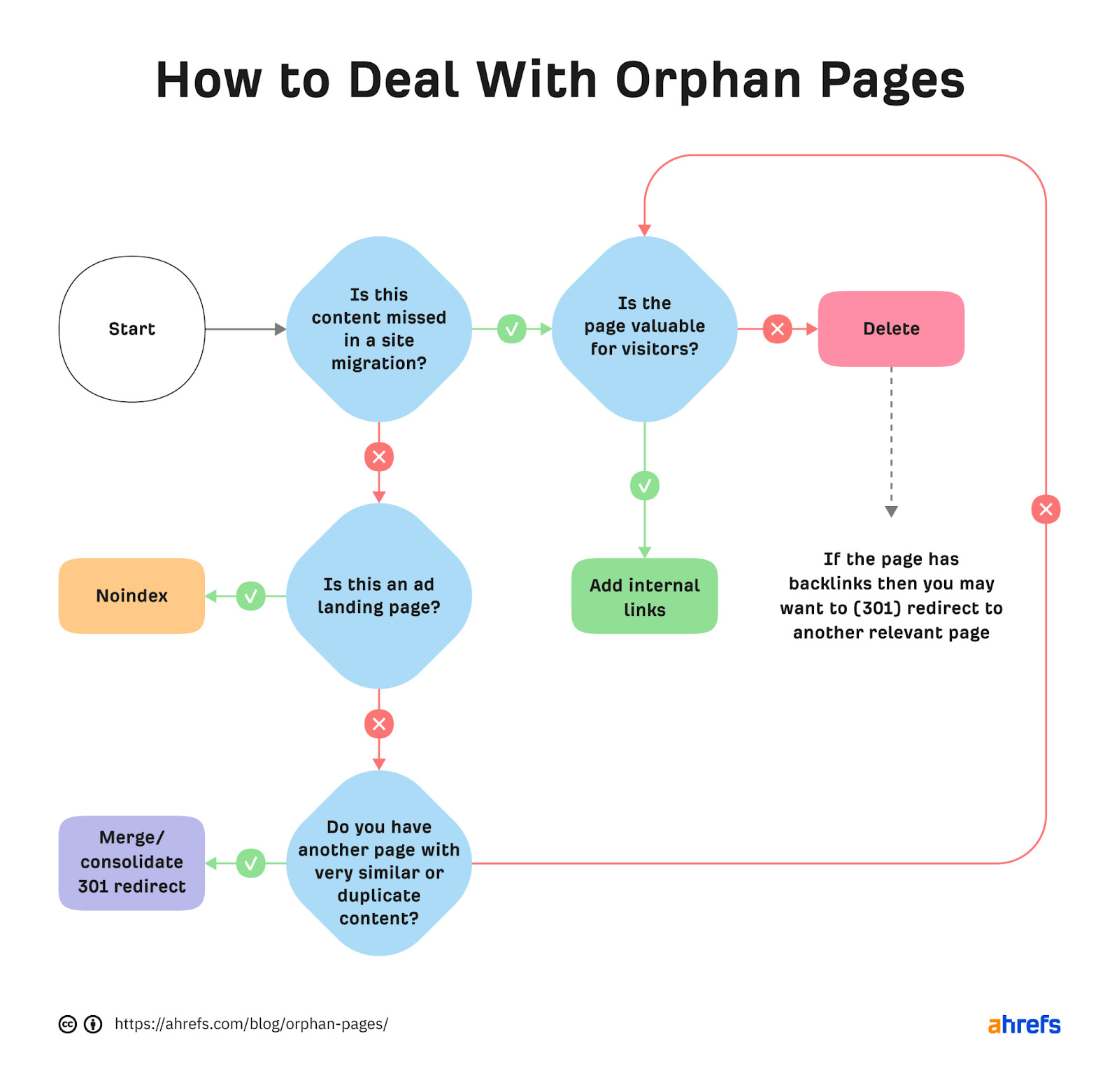
The idea here is to think critically about each orphan page and decide whether noindexing, deleting, merging/consolidating, or simply adding internal links is the best fix.
For example, if a page was missed during a site migration and that page does not offer any value for visitors, deleting is probably the best option. However, if the page has backlinks, it may also be worth redirecting the URL to another relevant page to preserve backlink equity.
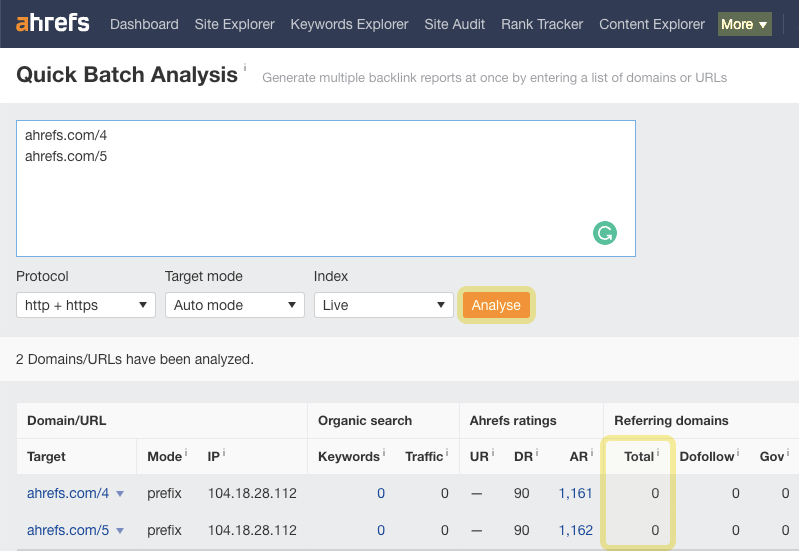
TIP
Checking orphan pages for backlinks in bulk (up to 200 URLs at a time) is easy with Ahrefs’ Batch Analysis tool. Just paste URLs from your cross reference sheet and click Analyse.
Let’s look at the four strategies to fix orphan pages.
Internally link
Orphan pages that are valuable for site visitors should be incorporated into your site’s internal linking structure to make them easier for visitors and search engines to find.
For example, let’s say an article was forgotten during a site migration or redesign. We need to internally link to it from a relevant page we know Google will soon (re)crawl.
Here’s an easy way to do that in Ahrefs:
- Go to Site Audit
- Open your site’s most recent crawl
- Under Tools > Open Page Explorer.
- Search for a word or phrase in Page text.
- Sort the results by Organic traffic.
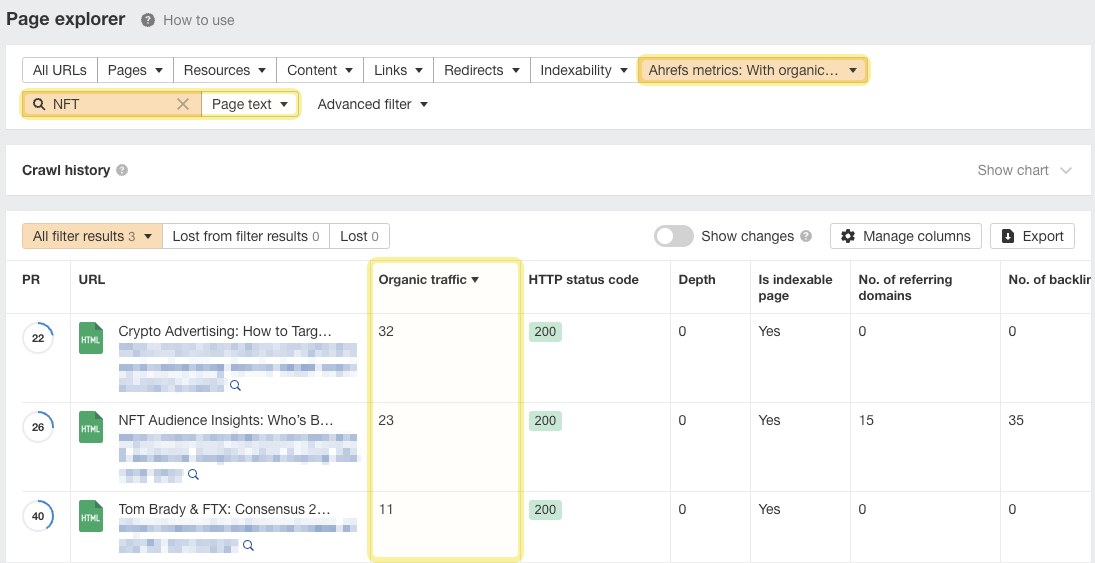
This finds contextual internal linking opportunities on pages that get organic traffic, which means Google is likely to recrawl them sooner rather than later and see our changes.
Learn more:How to Use Page Explorer
Noindex
Orphan pages that were intentionally not internally linked to, like landing pages for ads, should be noindexed to prevent them from appearing in organic search results.
Most SEO plugins have made this as easy as checking a box, but you can also do it manually by copying and pasting this into the <head> section of the page:
<meta name="robots" content="noindex" />
Sidenote.
Make sure these pages are still crawlable in robots.txt, otherwise search engines won’t see the noindex directive.
Merge/consolidate
Orphan pages with the same or similar content to another page should be merged. This means consolidating the content and redirecting the orphan URL to the other page.
For example, let’s say you have two product listings for the same product. One of them is an orphan page; the other isn’t. You should take any unique valuable information from the orphan page and add it to the other page before redirecting the orphan page there.
Delete
Orphan pages that offer no value for visitors and serve no other purpose (e.g., paid traffic campaign) should be deleted.
For example, an unused CMS theme page can be removed. This will result in a 404 page and naturally drop out of search results over time.
Sidenote.
If the page has backlinks, you may want to redirect the URL to another relevant page to preserve link equity after deleting.
As you can see, auditing orphan pages is time-intensive. So once you’ve put in the work, you want to prevent orphan pages in the future. Here are a few policies and procedures to consider.
Have a plan for site migrations
Be proactive by having a plan any time you do a website migration. You can avoid broken links and confusion on your website by redirecting old…
[ad_2]
